Retrieval Is All You Need
FullStackRetrieval.comMy new home for retrieval related content |
Welcome to the 135 people who have joined us since last week! If you aren’t subscribed, join 3,189 smart AI folks. View this post online.
The bottleneck is not GPT-4GPT-4 is actually pretty smart, ask it to make a decision, and you’ll likely get the right answer. This led me to a realization, the limits of our ability to do more with Large Language Model (LLMs) isn’t necessarily the model itself, but rather the information we give it. Give GPT-4 the right information and you’ll provide value to users. So it’s not a reasoning challenge, it’s a retrieval challenge. Retrieval is the process of gathering, storing, and serving your applications the data it needs. The concept of serving applications data is as old as computing itself, but in the unstructured world of LLM application building, new a retrieval mindset help us make magic. All my optimization strategies came back to retrieval. I constantly think about:
Retrieval is the umbrella that covers most of your application building. It’s the iceberg under your front end. It’s also extremely hyped (2nd to only agents and maybe evals). But yet it’s still massively underrated. As an educator in space I have a keen eye on how information is presented - with retrieval, I haven’t seen the take on it that I want to see. So I'm taking a stab at fixing this. My retrieval content is finally getting a home: FullStackRetrieval.com FullStrackRetrieval.com Trailer (As a subscriber you're getting the beta access, you may seem some rough edges, I'll launch on Twitter later) First thing new members will get is 1 advanced retrieval method a day for 5 days sent to them. This will include:
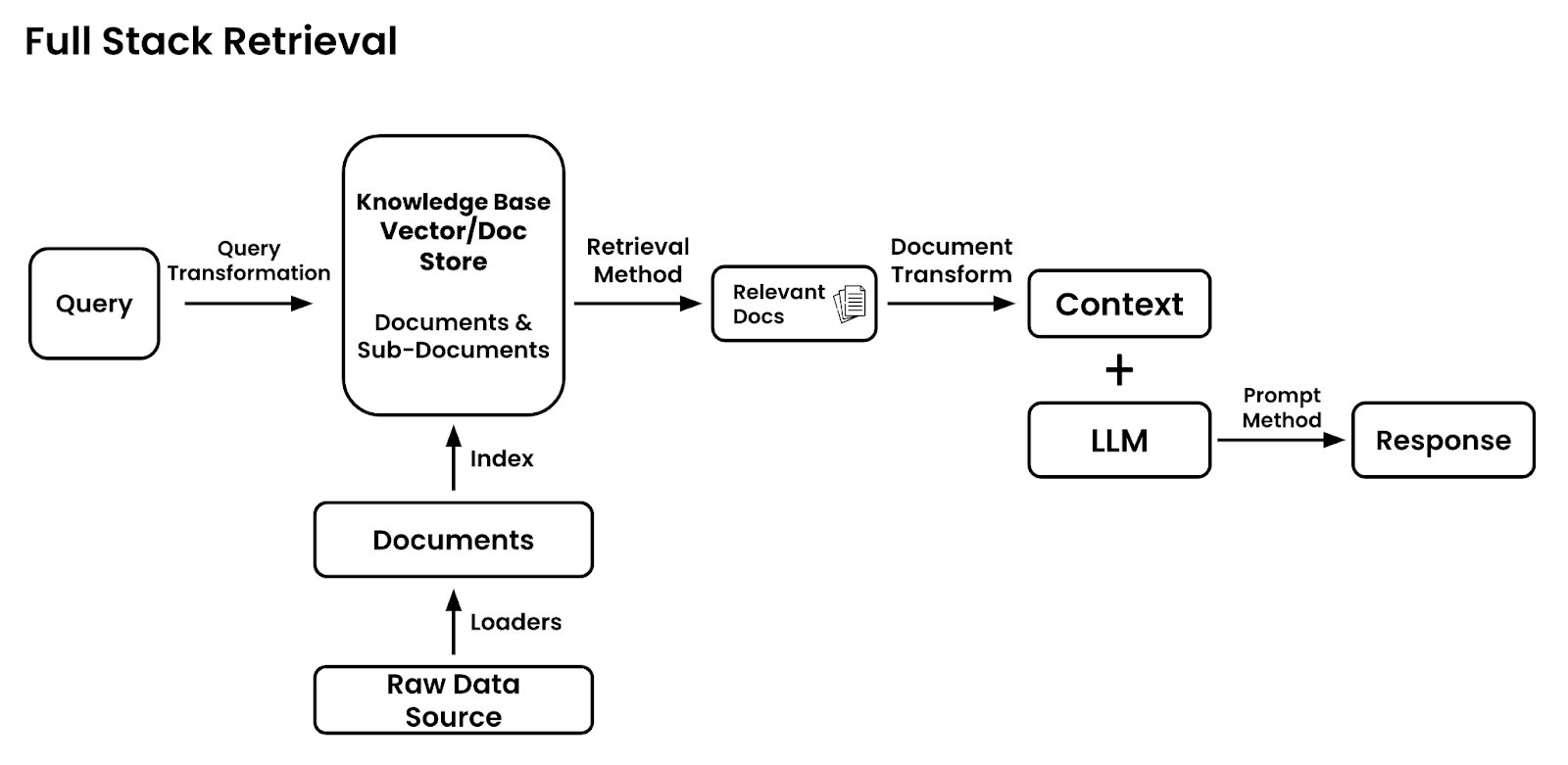
When I try to understand topics I need to start with the big picture, then understand how its sub-components relate to each other. Instead of thinking about retrieval in the abstract, here is my “least-wrong” tactical view.
Let’s break down into parts:
The point isn’t to cover 100% of retrieval permutations, but rather have a starting point for a discussion. I tried bullet-proofing this view on twitter, but I’d love your feedback, what do you think? All of the content is free for now, I may do some paywall in the future but as friends, email me and you’ll get the family discount. I’d love to hear a few things from you:
In case you missed it
Greg Kamradt Twitter / LinkedIn / Youtube / Work With Me |
Greg's Updates & News
AI, Business, and Personal Milestones
Sully Omar Interview 2 years of building with LLMs in 35 minutes Welcome to the 100 people who have joined us since last week! If you aren’t subscribed, join 9,675 AI folks. View this post online. Subscribe Now Sully, CEO Of Otto (Agents in your spreadsheets) came on my new series AI Show & Tell I reached out to him because you can tell he feels the AI. His experience is not only practical, it's battle tested. Sully's literally built a product of autonomous async agents that do research for...

Joining ARC Prize How the cofounder of Zapier recruited me to run a $1M AI competition Welcome to the 2,450 people who have joined us since last post! If you aren’t subscribed, join 9,619 AI folks. View this post online. Subscribe Now "We gotta blow this up." That's what Mike Knoop (co-founder of Zapier) says to me in early 2024. "ARC-AGI, we gotta make it huge. It's too important." "Wait, ARC? What are you talking about?" I quickly reply. "It's the most important benchmark and unsolved...
Building a business around a commodity OpenAI's models are a commodity, now what? Welcome to the 296 people who have joined us since last week! If you aren’t subscribed, join 3,939 AI folks. View this post online. Subscribe Now Large Language Models are becoming a commodity. We all know it. So if you’re a foundational model company, what do you do? You build a defensible business around your model. You build your moat. Google famously said they have no moat, “and neither does OpenAI.” But...